Overview
Machine Learning
Data Mining
Data Management
Machine Learning
Data Mining
Data Management
 |
Why do we need graph representation learning? Graph is a general data structure used to encode relational data, such as online social networks, syscall logs in cybersecurity, and many others. Intuitively, from graphs, one could derive contextual features for better decision making. For example, instead of predicting a user's interest solely based on the data of this user, one may look into his/her contextual information, which is the data from this user's close friends or friends' friends in this case. By jointly considering personal and contextual features, one could make more accurate prediction even when a specific user's data are sparse. With the significant value in contextual features, graph representation learning is to learn vector representations for individual nodes, edges, or graphs that encode salient and discriminative contextual features for downstream analytical tasks. Why is it hard to learn graph representations? The key barrier is the difficulty in defining contextual features. In general, contexts could be something vague, and the exact forms could be task-specific, or even case-specific. Traditional methods attempt to address this challenge by heavey feature engineering. For example, one could suggest a triangle substructure is critical, and the count of triangles within one-hop of a node as one of this node's contextual features. While it is impractical to enumerate all combinatorial possibilities, the resulting performance could be limited as pre-defined features may not even be relevant with regard to a specific task. In 2015, the question in my mind was given labels of a specific task, why don't we let machines automatically figure out which features are informative for prediction? In short, it is the irregular structure and permutation invariance requirement that make it difficult to adapt the learning methods back then for graph representation learning. My perspectives. My research touches three dimensions of graph representation learning techniques: functionality, generalization, and interpretation. Working with my colleauges at NEC Labs, we have developed machine learning techniques that enhance the three dimensions. Publications |
 |
In this broad area, my current research focuses on the following topics. Feature extraction from texts of multi-facet information. Text descriptions of experts or products usually cover multi-facet information supported by corresponding sentences. In recommendation tasks, it is critical to locate relevant information conditioned on queries. In the context of question routing [WSDM'20] and recommendation [AAAI'20 A], we developed deep architectures that leverage attention conditioned on queries to recognize relevant sentences or features. Our techniques achieve state-of-the-art performance on public benchmark datasets. I am currently working on the following two topics. More information will come soon. Publications |
 |
Density estimation is the core of anomaly detection: anomalous samples are usually far away from dense areas where normal samples reside. In this line of research, I focus on the following topics. Anomaly detectors. It is always a challenging task to perform anomaly detection for high-dimensional data, as all samples in high-dimensional space seem to be far away from each other. In [ICLR'18], we proposed a deep architecture named DAGMM that simultaneously performs dimension reduction and density estimation in a joint reduced and error space. On multiple public benchmark datasets, DAGMM achieves state-of-the-art detection accuracy. In addition, an extension of DAGMM is able to boost performance in clustering tasks [SDM'19]. Anomaly detection for system log data. System logs include key information that indicates system health status. As one of the key developers, my colleagues and I have built a log analytics system named NGLA which parses heterogeneous system logs without domain knowledge and detects system anomalies in real-time [ICDCS'18]. Anomaly detection for Multivariate time series. We developed a deep architecture that encodes multivariate time series into a joint reduced and error space. In the learned space, our technique achieves significant improvement in detection accuracy for multivariate time series [AAAI'19]. Publications |
 |
A quick intro on imitation learning. The goal of imitation learning is to let machines automatically learn skills from expert demonstrations. Unlike traditional reinforcement learning, imitation learning aims to skip or automatically learn the latent reward function that impacts experts' decision making. Behavior cloning and inverse reinforcement learning are two major imitation learning techniques. Behavior cloning suffers poor generalization caused by compounding errors, and it is difficult to incorporate information from negative demonstrations into inverse reinforcement learning. Adversarial imitation learning. Our key insight is to improve generalization performance from positive demonstration and avoid repeating mistakes in negative demonsrations. With this key spirit, we have developed adversarial learning techniques to enforce state-action distribution of a learned policy to move closer to state-action distribution of positive demonstrations, and to move farther from state-action distribution of negative demonstrations [WWW'20]. Publications |
 |
In this line of research, we develop customized machine learning techniques for critical applications. Turbulence forecasting [ICDM'20]. Our main challenge comes from label data spasity. By a pre-trained turbulence detection model, our technique is able to generate pseudo labels. By combining true and pseudo labels, our deep learning technique has achieved significant performance improvement. Multivariate trend prediction [AAAI'20 B]. We formulate the trend prediction problem as a multi-task learning problem. A deep learning architecture is developed to allow history/memory sharing across different tasks. Our technique achieves state-of-the-art prediction performance on benchmark datasets. Multivariate time series retrieval [AAAI'20 C]. We aim to encode multivariate time series segments into vector representations for retrieval. In particular, we develop clustering constraints and adversarial training techniques to enhance the discriminative power and smoothness of learned vector representations. Our technique achieves state-of-the-art performance in time series retrieval tasks. Publications |
 |
System calls generated from computer systems form large-scale heterogeneous temporal graphs that capture the evolution of system activities over time. From this temporal graph, users can query known activity patterns related to system risks; however, these patterns are usually formed by primitive behaviors, such as remote-login, file compression, and so on, which cannot be directly found in the temporal graphs of basic system entities like processes, files, sockets, and pipes. To bridge the gap, we propose the idea of using discriminative sub-traces to represent primitive behaviors and build behavior queries, where the task of mining discriminative sub-traces is formulated as a temporal graph pattern mining problem. To overcome the mining speed issue, we leverage the temporal information in graphs to develop efficient pattern growth algorithms and prune search space with small overhead. Our mining algorithm is up to 90 times faster than the baselines, and the discovered behavior queries achieve high precision (97%) and recall (91%). Collaborator: NEC Lab America Publication |
 |
Alerts serve as indicators of malfunction in system performance analysis. While complex systems nowadays could generate tens of thousands of alerts per day, users like system administrators cannot handle these alerts one by one. In this context, we propose critical alert mining that automatically discovers critical alerts from system monitor data and helps users focus on the critical ones instead of blindly checking alerts. In particular, we build a temporal graph that captures the dynamic dependencies among system alerts, and infer top critical alerts from the temporal graph by cost-effective algorithms. Our approach is up to 5, 000 times faster than the baselines, and we do discover critical alerts from real-life system monitor data. Collaborator: LogicMonitor Publication |
 |
In a distributed stream processing system, it is important to pack user-defined queries into servers such that network cost in the system is minimized and load balance is preserved. In this work, we model the subscription relations between queries and data sources as temporal bipartite graphs where query nodes can dynamically join or leave the graphs, and formulate the query placement task as a partitioning problem. Due to the NP-hardness of the problem, we propose online/offline approximation algorithms with performance guarantees as well as cost-effective heuristics. Our algorithms practically work well in a wide range of scenarios, and are adopted in Microsoft products. Collaborator: Microsoft Research Publication |
 |
Cloud datacenter provides a reliable way to share computation resources. In a cloud datacenter, a routine task is to place cloud services: find a set of servers to host a user-defined cloud service. It is challenging to place cloud services, as cloud services usually include topology and computation resource requirements, and the underlying datacenter is dynamically evolving over time. In this work, we formulate the cloud service placement problem as a subgraph matching problem where cloud datacenters are modeled as large temporal graphs and cloud services are represented as small query graphs. With the observation that available computation resources are highly dynamic in a datacenter but its structure is relatively stable, we develop a graph encoding scheme that decomposes graph structures and node/edge attributes in graphs. A flexible graph index is developed based on the encoding scheme to enable fast index search and update. The proposed graph index achieves up to 10 times speedup for subgraph search, and can process 5M updates per second. Collaborator: IBM Research Publication |
 |
Information cascades are temporal graphs that model the traces of information propagation in online social media. On the one hand, they play vital roles in social science study as well as applications like online marketing. On the other hand, it is difficult to obtain complete structures for information cascades due to privacy policies and data noise. In this work, we aim to recover missing structures in cascades, and formulate this task as an optimization problem that searches the optimal way to connect cascade pieces subject to temporal constraints in cascades and structural constraints in online social media. Despite the NP-hardness of this problem, we propose efficient approximation algorithms with performance guarantees. Our approach significantly outperforms the baselines on recovering missing structures in real-life cascades. Publication |
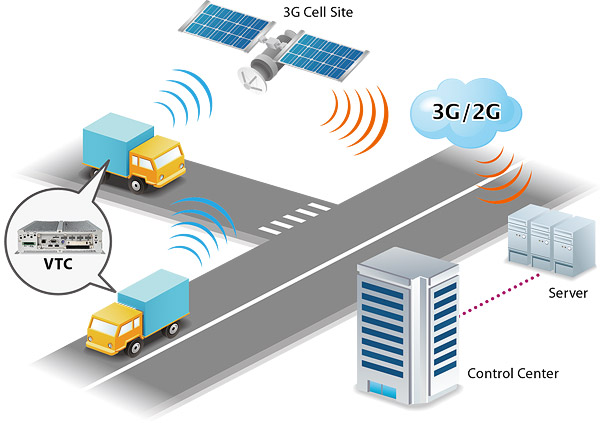 |
In a network of mobile objects like vehicle networks, it is challenging to spread information in a cost-effective way, due to the dynamic changes in network topology. In this work, we model a mobility network as a temporal graph, and formulate the information routing problem as a node reachability problem. Since an information routing request could involve millions of reachability queries, it is vital to efficiently process the queries for real-time response. To achieve this goal, we build a graph index by compressing temporal graphs into directed acyclic graphs, and process reachability queries in a batch via the graph index. Our method can dynamically find the optimal routing strategy for an incoming request in a few seconds, and the proposed graph index brings up to 100 times speedup to the process of searching optimal routing strategies. Publication |
|
Sedge is a software framework that supports large scale graph processing. Essentially, Sedge is inspired by Google’s Pregel. The Pregel like model is simply blind of intensive inter-machine communication and unbalanced workload. Sedge adds functions to support overlapping partitions, with the goal to process local graph queries faster. Sedge is able to minimize inter-machine communication by dynamically adapting graph partitions to query workload change, as well as data change. Publication |